
参考文献
本記事は
SBIネオモバイル証券のポートフォリオをCSVで取り込む【Python】
Pythonでつくる、株式ポートフォリオ
証券コードと業種の関係
pythonで日本株スクリーニング①
こちらを参考、一部コードの引用をおこなっております。
詳しい説明はこちらをご確認お願いします。
本記事ではコードからどんなイメージで理解すればよいかを解説します。
やりたいこと
SBIネオモバイル証券から自分が保有する株値、株数を取得する。
また、分析するためにグラフ化し、分散投資の計画を立てる。
今回のプログラミングポイント
pythonでのスクレイピング
htmlのタグを指定して値を取得
その他ポイント
自分のブログの参考ページ
今回のコード
import sys
import time
import datetime
from selenium import webdriver
from selenium.webdriver.support.ui import Select
import pandas
from bs4 import BeautifulSoup
import csv
from selenium.webdriver.common.by import By
def neomobile_login(neomobileusername,neomobilepassword):
chromedriver = “chromedriver.exeの場所をフルパスで指定してください。”
driver = webdriver.Chrome()
# ネオモバログインHP
driver.get(“https://trade.sbineomobile.co.jp/login”)
# 3秒待つ
time.sleep(3)
user = driver.find_element(By.NAME, “username”)
passwd = driver.find_element(By.NAME, “password”)
btn_login = driver.find_element(By.ID, “neo-login-btn”)
user.send_keys(neomobileusername)
passwd.send_keys(neomobilepassword)
btn_login.click()
# 1秒待つ
time.sleep(1)
return driver
def portfolio_list():
#ポートフォリオページにアクセス
driver.get(“https://trade.sbineomobile.co.jp/account/portfolio”)
time.sleep(2)
#最下部までスクロール
html01=driver.page_source
while 1:
#div class sp-main内をスクロール
#スクロール幅10000pixelで設定しています。3ページ読み込み程度では問題なく動きますが、上手くいかないようなら数字を大きくしてみてください。
driver.execute_script(“arguments[0].scrollTop =arguments[1];”,driver.find_element(By.CLASS_NAME, “sp-main”), 10000);
time.sleep(2)
html02=driver.page_source
if html01!=html02:
html01=html02
else:
break
# 文字コードをUTF-8に変換
html = driver.page_source.encode(‘utf-8’)
# BeautifulSoupでパース
soup = BeautifulSoup(html, “html.parser”)
#table(現在値〜預り区分をpandasで取得)
table = soup.findAll(“table”)
df_table = pandas.read_html(str(table))
#table数(保持銘柄数)
tableno=len(df_table)
#空のデータフレームを作成
list_df = pandas.DataFrame( )
#銘柄ごとにテーブルを取得し追加していく
for x in range(0,tableno):
s=df_table[x].iloc[:,1]
list_df=list_df.append(s)
#列名の付け直し
list_df.columns=[‘現在値前日比’,’保有数量’,’(うち売却注文中)’,’評価損益率’,’平均取得単価’,’預り区分’]
#indexを0から振る
list_df=list_df.reset_index(drop=True)
print(“テーブル抽出”)
list_df.to_csv(“ネオモバテーブル.csv”, encoding=”shift-jis”)
#コード、銘柄名、評価額、評価損益はclass名から1銘柄ずつ取得する
#コード
code_list=list()
for codes in soup.find_all(class_=”ticker”):
code=codes.get_text()
code=code.strip()
code_list.append(code)
df_code=pandas.Series(code_list)
#銘柄名
name_list=list()
for names in soup.find_all(class_=”name”):
name=names.get_text()
name=name.strip()
name_list.append(name)
#print(“銘柄名”)
#print(name)
df_name=pandas.Series(name_list)
#評価額
value_list=list()
for values in soup.find_all(class_=”value”):
value=values.get_text()
value_list.append(value)
df_value=pandas.Series(value_list)
#評価損益
rate_list=list()
for rates in soup.find_all(class_=”rate”):
rate=rates.get_text().strip()
rate=rate.replace(“評価損益”, “”)
rate=rate.replace(” “, “”)
rate=rate.replace(“\n”, “”)
rate=rate.replace(“円”, “”)
rate=rate.replace(“,”, “”)
rate_list.append(rate)
df_rate=pandas.Series(rate_list)
#コード〜評価損益を結合
df=pandas.concat([df_code,df_name,df_value,df_rate],axis=1)
#列名を更新
df.columns=[‘コード’,’銘柄名’,’評価額’,’損益’]
df_result=pandas.concat([df,list_df],axis=1)
df_result.index=df_result.index+1
#出力確認用
#df_result.to_csv(“ネオモバポートフォリオ.csv”)
#数値を扱いやすいように修正
#評価額
value=df_result[“評価額”].str.split(“\n”,expand=True)[1]
value=value.str.replace(‘,’,”)
#損益
rate=df_result[“損益”]
#現在値
price=df_result[“現在値前日比”].str.split(“円”,expand=True)[0]
price=price.str.replace(‘,’,”)
#前日比円
pricerate=df_result[“現在値前日比”].str.split(” / “,expand=True)[1]
pricerate=pricerate.str.split(” “,expand=True)[0]
pricerate=pricerate.str.replace(‘,’,”)
#前日比パーセント
pricepercent=df_result[“現在値前日比”].str.split(” “,expand=True)[1]
# pricepercent=pricepercent.str.split(” “,expand=True)[1]
pricepercent=pricepercent.str.split(“%”,expand=True)[0]
#保有数量
stock=df_result[“保有数量”].str.split(“株”,expand=True)[0]
stock=stock.str.replace(‘,’,”)
#売却注文中
stocksell=df_result[“(うち売却注文中)”].str.split(“株”,expand=True)[0]
stocksell=stocksell.str.replace(‘,’,”)
#評価損益率
percentage=df_result[“評価損益率”].str.split(“%”,expand=True)[0]
#平均取得単価
aveprice=df_result[“平均取得単価”].str.split(” “,expand=True)[0]
aveprice=aveprice.str.replace(‘,’,”)
#データフレームを結合
df_result2=pandas.concat([df_result[“コード”],df_result[“銘柄名”],value,rate,price,stock,stocksell,percentage,aveprice,df_result[“預り区分”]],axis=1)
df_result2.columns=[‘コード’,’銘柄名’,’評価額(円)’,’損益(円)’,’現在値(円)’,’保有数量(株)’,’(うち売却注文数)(株)’,’評価損益率(%)’,’平均取得単価(円)’,’預り区分’]
return df_result2
def export_data(df_result, name):
df_result2.to_csv(name + ‘.csv’, encoding=”shift-jis”)
if __name__ == ‘__main__’:
# SMBC日興ログインアカウント
neomobileusername = “ログインユーザ名”
neomobilepassword = “パスワード”
name=”SBIネオモバイルポートフォリオ(csv出力時のファイル名)”
#ログイン
driver=neomobile_login(neomobileusername,neomobilepassword)
#注文中リストの書き出し
df_result2=portfolio_list()
export_data(df_result2,name)
driver.quit()
解説
スクレイピングとは
まず、スクレイピングとは簡単に説明すると
webページからデータを収集する行為のことです。詳しい説明は検索していただいたり、以下のwikipediaなどを参考にしてください。
スクレイピング-wiki
本記事ではスクレイピングのイメージとそのイメージをコードに反映する方法を解説します。
スクレイピングのイメージ
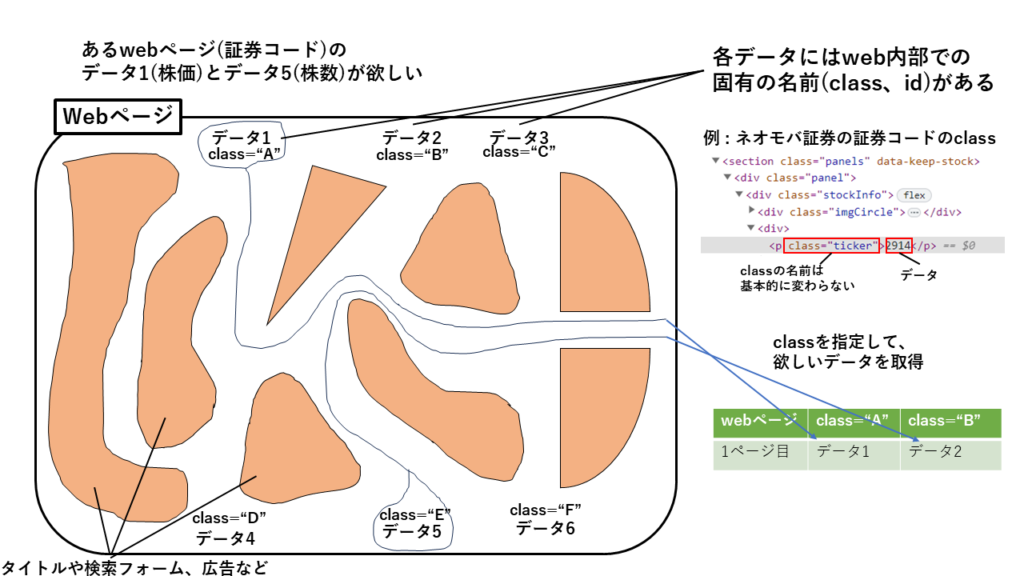
スクレイピングのイメージですが、上の図を参考にしてください。(パワーポイントで作成のでわかりにくければすみません。)
まず、webページはいろいろな要素から作成されています。例えば、タイトル、検索フォーム、文書、広告などです。
そして、その要素には名前が付けられています。名前の総称をタグとしましょう。タグにもいろいろな種類があります。
(自分の記事を作成し、説明します)
いろいろなタグがあり、混在する場合があります。
そこで、web内部で区別するためにweb作成者自身で名前を付けている場合があります。
例えば、上図にネオモバ証券に使われているタグを示しました。その中に、<p>がタグになります。
そのたタグにclass=”ticker”という名前をつけています。これはネオモバ証券のweb作成者が命名したものになり、基本的に変化しません。
変化するところは<p></p>で囲まれた数字や文章、いわゆるデータです。上図で示した例では2914という数字がデータで証券コードです。スクレイピングの場合、このclassやidで名前が付けられた箇所を探し、その名前に合致したデータを取得します。
文章だけだと難しいですが、上図の作成した△や〇などの集まった変な絵を見てください(笑)。これが私の中のスクレイピングのイメージです。
webページという大きな囲いの中にオレンジ色の要素があり、その一部にデータがあります。変な絵の右に描いた楕円を4分割した2つの隙間から線が出て、データ1、データ5に伸びているかと思います。
隙間が自分がいる位置で、某アニメの主人公のように手をゴムのように伸ばしてデータをつかむようなイメージです。このイメージでは自分が動かず、手だけが動いてデータを探しています。
イメージを反映させてみよう
これをコンピュータに移植しましょう。
まず、コンピュータは文字の形しか見ていません。文字や数字に意味があるとは思っていません。そこで、人間が手を与えて、①いろいろ探してもらいます。そして、見つかったら掴んで我々のところまで②持ってきてもらいましょう。
人間が手を与えるにはコードを書きます。探す作業は名前の字の形を参照しましょう。持ってきてもらう作業は箱をつくってその中にデータを入れもらいましょう。で
は、今回のコードの中にイメージを反映した箇所を以下にしめします。
イメージを反映しているコード
code_list=list()
for codes in soup.find_all(class_="ticker"):
code=codes.get_text()
code=code.strip()
code_list.append(code)code_listはデータを入れる箱です。今回はlist()というタイプです。
soup.find_all(class=”ticker”)でtickerという名前に合致しているタグをすべて見つけてもらいしょう。
見つけてもらったタグの中から1つだけ取り出し、codesという名前を一時的に与えます。
そのcodesからデータを取得し、codeという名前を一時的に与えます。
code.strip()はデータを見やすくする処理です。今回は本質的ではないので割愛。
最後の行で最初に用意した箱にデータを入れます。
これをすべてのタグに対して行います。(15分で分かるプログラミング基礎(ループでデータを処理する参考)
人間がやったら何時間かかるのでしょうか。某アニメの主人公ならゴムゴムのピストルでたくさんデータ持ってこれそうですが。
いかがでしょうか?イメージをコードに反映する方法がわかりましたでしょうか?
少しでもわかっていただけたら幸いです。
ここまで読んでいただき、ありがとうございました。
2023/7/28 J.A

コメント