はじめに
これまでAIの基礎について勉強していました。また、いろいろな手法やライブラリについても調べてきてAIを研究開発するのに必要な知識を身に着けてきました。
そこで今回から本格的にAIについて研究していきます!
今回はRNNをつかって株価予想をしていきたいと思います。
最終ゴール
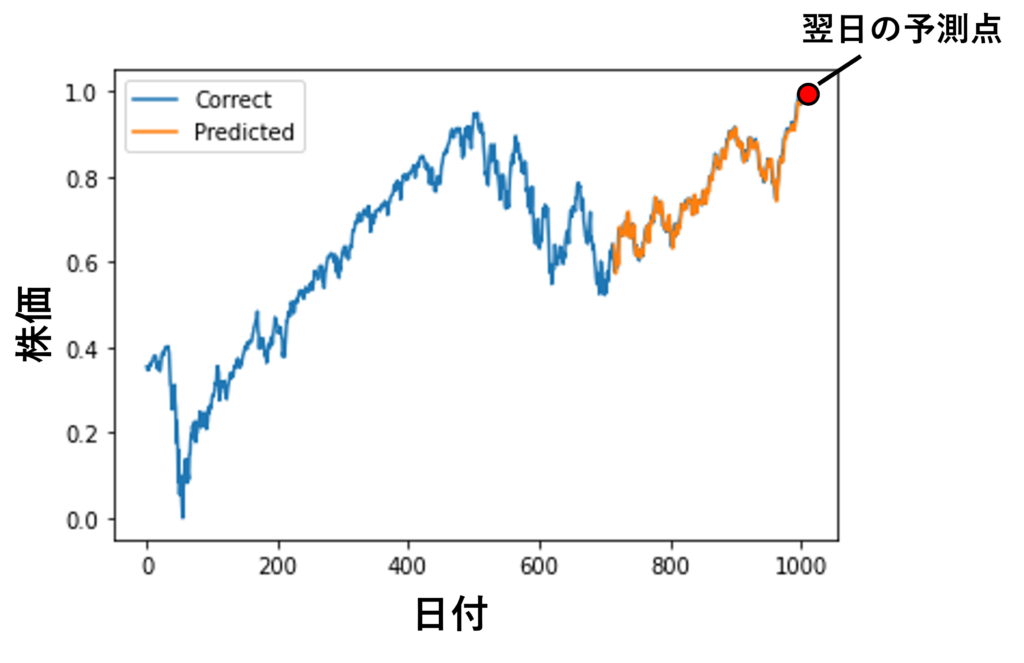
最終ゴールは以下のような図ができ、翌日の株価を予想することです。
まずはChatGPTに聞いてみよう
pytorchでrnnを実装して
PyTorchを使用してRNN(Recurrent Neural Network)を実装するためには、以下の手順に従うことが一般的です。以下に、シンプルなRNNの例を示します。
import torch
import torch.nn as nn
# RNNモデルの定義
class SimpleRNN(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(SimpleRNN, self).__init__()
self.hidden_size = hidden_size
self.rnn = nn.RNN(input_size, hidden_size, batch_first=True)
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x):
# RNNのforward
out, _ = self.rnn(x)
# 最後の時刻の隠れ状態を取得
out = self.fc(out[:, -1, :])
return out
# モデルのインスタンス化
input_size = 10 # 入力の特徴量の数
hidden_size = 20 # RNNの隠れ層のサイズ
output_size = 1 # 出力のサイズ
model = SimpleRNN(input_size, hidden_size, output_size)
# 損失関数と最適化関数の定義
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
# ダミーデータの生成
batch_size = 32
sequence_length = 5
dummy_input = torch.rand((batch_size, sequence_length, input_size))
# 学習のループ
num_epochs = 100
for epoch in range(num_epochs):
# Forward
outputs = model(dummy_input)
# Lossの計算
loss = criterion(outputs, torch.rand((batch_size, output_size)))
# Backwardとパラメータの更新
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 途中結果の表示
if (epoch+1) % 10 == 0:
print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}')この例では、nn.RNNモジュールを使用してRNNを定義しています。nn.Linearを使用して、RNNの最後の時刻の隠れ状態から出力を生成しています。最後に、損失関数と最適化関数を定義し、学習ループを実行しています。適切なデータセットとタスクに合わせてモデルを変更してください。
動作はしてくれますが、より汎用的なもので実装したいので、具体的な日付とそれに対する時系列データで実装できるようにしてもらいましょう。
1992/1/1 788
1992/2/1 679
1992/3/1 692
1992/4/1 656
1992/5/1 697
1992/6/1 725
1992/7/1 775
1992/8/1 811
1992/9/1 795
1992/10/1 820
のような時系列データを読み込んで行う方法も実装して
時系列データを取り扱う場合、まずはデータの読み込みから前処理、モデルの設定、学習、予測などを行います。以下に、与えられた時系列データを取り扱うための簡単な例を示します。この例では、PyTorchを使用してRNNを設定し、与えられたデータを学習して未来の値を予測するものです。
import torch
import torch.nn as nn
import numpy as np
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
# 時系列データの読み込み
data = """
1992/1/1 788
1992/2/1 679
1992/3/1 692
1992/4/1 656
1992/5/1 697
1992/6/1 725
1992/7/1 775
1992/8/1 811
1992/9/1 795
1992/10/1 820
"""
# データの整形
data = [line.split() for line in data.strip().split('\n')]
dates, values = zip(*data)
values = list(map(float, values))
# データの正規化(0から1の範囲に変換)
scaler = MinMaxScaler()
values_normalized = scaler.fit_transform(np.array(values).reshape(-1, 1))
values_normalized = values_normalized.flatten()
# データのPyTorch Tensorへの変換
values_tensor = torch.FloatTensor(values_normalized).view(-1, 1)
# シーケンスデータの作成
def create_sequences(data, sequence_length):
sequences = []
targets = []
for i in range(len(data) - sequence_length):
seq = data[i:i+sequence_length]
target = data[i+sequence_length:i+sequence_length+1]
sequences.append(seq)
targets.append(target)
return torch.stack(sequences), torch.stack(targets)
# パラメータの設定
sequence_length = 3 # 例として3つの時点を使って次の時点を予測する
# 入力データと目標データの作成
input_sequences, target_values = create_sequences(values_tensor, sequence_length)
# RNNモデルの定義
class SimpleRNN(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(SimpleRNN, self).__init__()
self.hidden_size = hidden_size
self.rnn = nn.RNN(input_size, hidden_size, batch_first=True)
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x):
out, _ = self.rnn(x)
out = self.fc(out[:, -1, :])
return out
# モデルのインスタンス化
input_size = 1 # 特徴量の数(1次元の時系列データなので1)
hidden_size = 64
output_size = 1
model = SimpleRNN(input_size, hidden_size, output_size)
# 損失関数と最適化関数の定義
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
# 学習のループ
num_epochs = 1000
for epoch in range(num_epochs):
# Forward
outputs = model(input_sequences)
# Lossの計算
loss = criterion(outputs, target_values)
# Backwardとパラメータの更新
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 途中結果の表示
if (epoch+1) % 100 == 0:
print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}')
# 未来の値を予測
future_sequence = torch.FloatTensor(values_normalized[-sequence_length:]).view(1, -1, 1)
predicted_value_normalized = model(future_sequence).item()
# 予測値を元のスケールに戻す
predicted_value = scaler.inverse_transform(np.array([[predicted_value_normalized]]))
print(f'Predicted Value: {predicted_value[0][0]:.2f}')コードの修正と調査
これもうまく動きました。しかし、時系列データが短いからか損失関数のlossが全然減っていません。試しにcsvを読めるようにして、長い時系列データで試してみます。
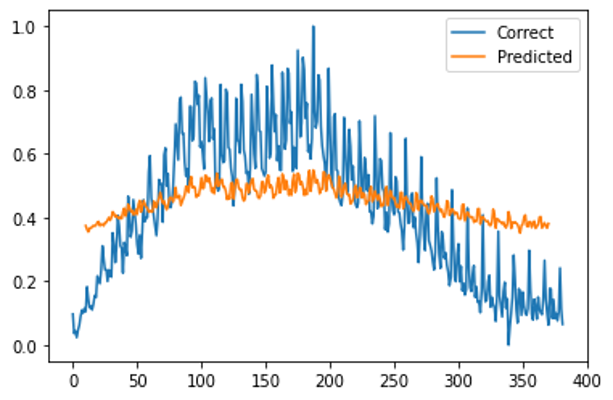
青線が実際の株価。オレンジ線が予測した株価です。
あまり精度が良くありません。少し考察していきます。
これまで勉強してきたとコードを見比べると学習用のデータと検証用のデータが分かれていないので、考察するにも何が精度を落としているか分かりません。
そこで、学習用、検証用に分けれらるように書き換えてきます。
こちらを参考にしました。
修正した最終版
最終形がこちら
import torch
import torch.nn as nn
from torch.utils.data import DataLoader, TensorDataset, Dataset
import numpy as np
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
import matplotlib.pyplot as plt
data = pd.read_csv(".csv")
X = data["DATE"]
Y = data[""]
data["DATE"] = data["DATE"].str.replace("-", "/")
data = data.to_string(header=False, index=False)
# データの整形
data = [line.split() for line in data.strip().split('\n')]
dates, values = zip(*data)
values = list(map(float, values))
# データの正規化(0から1の範囲に変換)
scaler = MinMaxScaler()
values_normalized = scaler.fit_transform(np.array(values).reshape(-1, 1))
values_normalized = values_normalized.flatten()
# RNNモデルの定義
class SimpleRNN(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(SimpleRNN, self).__init__()
self.hidden_size = hidden_size
self.rnn = nn.RNN(input_size, hidden_size, batch_first=True)
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x):
out, _ = self.rnn(x)
out = self.fc(out[:, -1, :])
return out
train_size = int(len(values_normalized) * 0.7)
test_size = len(values_normalized) - train_size
train = values_normalized[:train_size]
test = values_normalized[train_size:]
sequence_length = 10
n_sample = train_size - sequence_length - 1
input_sequences = np.zeros((n_sample, sequence_length, 1))
target_values = np.zeros((n_sample, 1))
for i in range(n_sample):
input_sequences[i] = values_normalized[i:i+sequence_length].reshape(-1, 1)
target_values[i] = values_normalized[i+sequence_length:i+sequence_length+1]
input_sequences = torch.tensor(input_sequences, dtype=torch.float).to(device)
target_values2 = torch.tensor(target_values, dtype=torch.float).to(device)
dataset = TensorDataset(input_sequences, target_values2)
train_loader = DataLoader(dataset, batch_size=4, shuffle=True)
n_sample_test = test_size - sequence_length - 1
test_data = np.zeros((n_sample_test, sequence_length, 1))
correct_test_data = np.zeros((n_sample_test, 1))
for i in range(n_sample_test):
test_data[i] = test[i : i+sequence_length].reshape(-1, 1)
correct_test_data[i] = test[i+sequence_length : i+sequence_length+1]
test_sequences = torch.tensor(test_data, dtype=torch.float).to(device)
target_values3 = torch.tensor(correct_test_data, dtype=torch.float).to(device)
dataset_test = TensorDataset(test_sequences, target_values3)
test_loader = DataLoader(dataset_test, batch_size=4, shuffle=False)
input_size = 1
hidden_size = 64
output_size = 1
model = SimpleRNN(input_size, hidden_size, output_size).to(device)
loss_fnc = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
loss_list = []
loss_list_test = []
epochs = 2000
for i in range(epochs+1):
model.train()
running_loss =0.0
running_loss_test =0.0
for j, (x, t) in enumerate(train_loader):
optimizer.zero_grad()
y = model(x)
loss = loss_fnc(y, t)
loss.backward() #逆伝番
optimizer.step()
running_loss += loss.item()
running_loss /= j+1
loss_list.append(running_loss)
for l, (x_test, t_test) in enumerate(test_loader):
y_test = model(x_test)
loss_test = loss_fnc(y_test, t_test)
running_loss_test += loss_test.item()
running_loss_test /= l+1
loss_list_test.append(running_loss_test)
if i%10 == 0:
print('Epoch:', i, 'Loss_Train:', running_loss, 'Loss_test:', running_loss_test)
input_train = list(input_sequences[0].reshape(-1))
predicted_train_plot = []
model.eval()
for k in range(n_sample):
x = torch.tensor(input_train[-sequence_length:]).to(device)
x = x.reshape(1, sequence_length, 1)
x = x.float()
y = model(x)
if k <= n_sample-2:
input_train.append(input_sequences[k+1][sequence_length-1].item())
predicted_train_plot.append(y[0].item())
plt.plot(range(len(values_normalized)), values_normalized, label='Correct')
plt.plot(range(sequence_length, sequence_length+len(predicted_train_plot)), predicted_train_plot, label='Predicted')
plt.legend()
plt.show()
plt.plot(range(len(loss_list)), loss_list, label='train')
plt.plot(range(len(loss_list_test)), loss_list_test, label='test')
plt.legend()
plt.xlabel("epochs")
plt.ylabel("loss")
plt.show()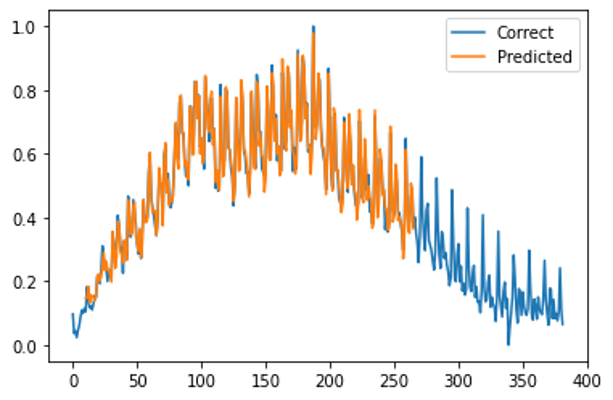
いいじゃないの!
検証データでも精度確認
検証用のデータもプロットしてみて
input_test = list(test_data[0].reshape(-1))
predicted_test_plot = []
model.eval()
for k in range(n_sample_test):
x = torch.tensor(input_test[-sequence_length:])
x = x.reshape(1, sequence_length, 1)
x = x.float()
y = model(x)
if k <= n_sample_test-2:
input_test.append(test_data[k+1][sequence_length-1].item())
predicted_test_plot.append(y[0].item())
plt.plot(range(len(values_normalized)), values_normalized, label='Correct')
plt.plot(range(sequence_length+train_size, sequence_length+len(predicted_test_plot)+train_size), predicted_test_plot , label='Predicted')
plt.legend()
plt.show()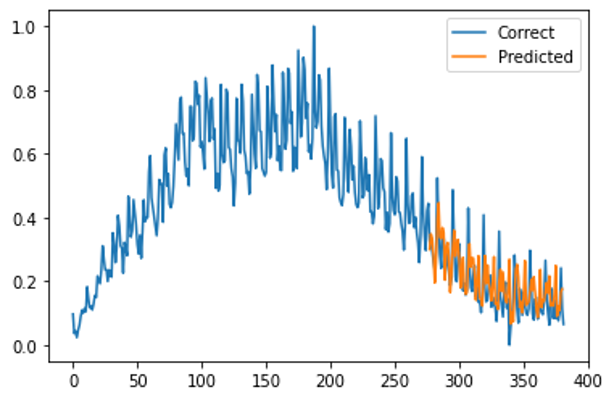
こちらもいいんじゃないの!
ところで何が良くなかったのでしょう…
探してみましたが、現在も不明です。調査を続けます。
未来のデータも予測
では、未来のデータも予測しちゃいましょう。
# 未来の値を予測
future_sequence = torch.FloatTensor(values_normalized[-sequence_length:]).view(1, -1, 1)
predicted_value_normalized = model(future_sequence).item()
# 予測値を元のスケールに戻す
predicted_value = scaler.inverse_transform(np.array([[predicted_value_normalized]]))
print(f'Predicted Value: {predicted_value[0][0]:.2f}')
fig, ax = plt.subplots()
ax.plot(range(len(values_normalized)),Y)
ax.scatter(len(values_normalized) + 1, predicted_value, color="red")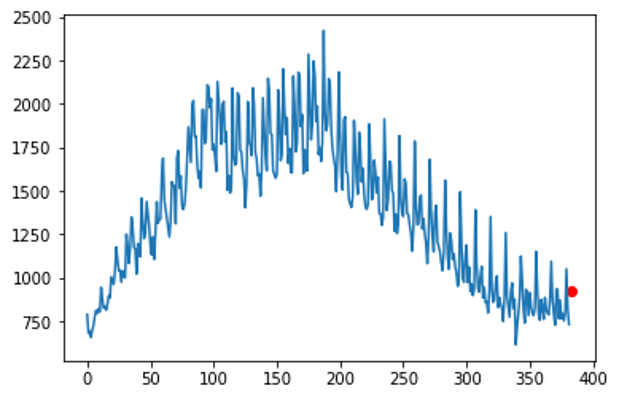
赤点が未来のデータです。ちなみに数字は919.59となりました。
前日が731なので、すごい上昇しますね。
最後に
とりあえず、株価の予測ができました。次からは色々な株価を予想してみて予測の幅を見てみたいと思います。


コメント