はじめに
前回はAIの手法について軽く調査し、tensorflowという手法で研究開発していくことを決めました。今回は前回ChatGPTで聞いたコードを一つずつ紐解いていきたいと思います。
コード解説
コード全体
まずは前回のtensorflowのコードです。
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.datasets import mnist
from tensorflow.keras.utils import to_categorical
# MNISTデータセットの読み込み
(X_train, y_train), (X_test, y_test) = mnist.load_data()
# データの前処理
X_train = X_train.reshape((X_train.shape[0], -1)).astype('float32') / 255
X_test = X_test.reshape((X_test.shape[0], -1)).astype('float32') / 255
y_train = to_categorical(y_train, 10)
y_test = to_categorical(y_test, 10)
# モデルの構築
model = Sequential([
Dense(128, activation='relu', input_shape=(784,)),
Dense(64, activation='relu'),
Dense(10, activation='softmax')
])
# モデルのコンパイル
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
# モデルのトレーニング
model.fit(X_train, y_train, epochs=10, batch_size=32)
# テストデータでモデルを評価
loss, accuracy = model.evaluate(X_test, y_test)
print(f"Loss: {loss}, Accuracy: {accuracy}")今回はライブラリとMNISTの読み込み、データの前処理について調べていきたいと思います。
ライブラリ
まずは、ライブラリです。pythonのライブラリについてはこちらの記事でも書きました。
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.datasets import mnist
from tensorflow.keras.utils import to_categoricaltensorflowについて
基本的なライブラリはtensorflowで構成されているようです。tensorflowについて簡単に調査してみました。
私にとって興味深そうなことがたくさん書かれていますが、後で再調査します。
kerasについて
ライブラリを見ていきます。
tensorflowの一つ下の階層がkerasというライブラリのようです。kerasを簡単に調べるとAIを短いコードで書けるようにしたコードの集まりのようです。
kerasの下にmodels、layers、datasets、utilsとあるようです。
modelについて
modelsはAIモデルともいわれているようで、AIがどういったプロセス(例えば、本で学習するとか動画で学習するとか)で学習する方法のようです。中でもライブラリに書かれているSequentialが一般的な方法らしく(参考)入力に対して前から順々に学習しているようです。学生時の教科書を前から順々に学んでいくプロセスみたいです。
layersについて
次にlayersです。ニューラルネットワークの要なようです。キーワードとしてニューロンや隠れ層などなようです。ニューロン数や隠れ層の数が増えればより複雑なAIが作ることができるようですが、しばらくはデフォルトのものを使っていきます。
datasetsについて
次にdatasetsです。AIの開発や初学者に向けたデータの集まりを提供しているようです。英語のサイトですが以下にたくさんのデータの集まりの解説をしています。
中でもよく使われているのはmnistと呼ばれる数字の判別に使うデータの集まりのようです。
utilsについて
最後にutilsです。これはAIが判別しやすいように変換したりする操作のようです。今回はto_categoricalというOne-Hotという0と1だけに変換する操作のようで、ラベルを分かりやすく示しているようです。例えば、以下に示すような0のラベルを示すのに0~9までの配列があって0番目が1で1番目から9番目が0にしたりできるようです。
0 : [1, 0, 0, 0, 0, 0, 0, 0, 0, 0]
1 : [0, 1, 0, 0, 0, 0, 0, 0, 0, 0]
2 : [0, 0, 1, 0, 0, 0, 0, 0, 0, 0]
3 : [0, 0, 0, 1, 0, 0, 0, 0, 0, 0]
4 : [0, 0, 0, 0, 1, 0, 0, 0, 0, 0]
5 : [0, 0, 0, 0, 0, 1, 0, 0, 0, 0]
6 : [0, 0, 0, 0, 0, 0, 1, 0, 0, 0]
7 : [0, 0, 0, 0, 0, 0, 0, 1, 0, 0]
8 : [0, 0, 0, 0, 0, 0, 0, 0, 1, 0]
9 : [0, 0, 0, 0, 0, 0, 0, 0, 0, 1]
今回の「to_categorical(y_train, 10)」はy_trainというデータを0~9までのラベルに分けるという意味になるようです。
以上がライブラリの調査結果です!長かったですね(笑)
データの読み込み
次にデータの読み込みです。
(X_train, y_train), (X_test, y_test) = mnist.load_data()ライブラリで説明したmnistを呼び出して、load_data()という関数でデータを呼び出しているようです。呼び出した結果を4つに分類してx_train、y_train、x_test、y_testに格納しています。
これらの違いについて簡単に調査しました。
インプットデータとアウトプットデータ
まずはxとyについてですが、
xはインプットデータでyがアウトプットデータのようです。
ここではxが目で見た数字でyが脳でその数字を判断した結果になると思います。
次にtrainとtestについてです。
trainはtrainingの略で「学習」という意味のようです。
testはそのままテストのようです。
trainで学習した結果をtestできちんと学習されているかテストするためにあるようです。
他にも検証用データがあるよう(参考)ですが、いつか勉強しましょう。
つまり、
x_train : trainのインプットデータ
y_train : trainのアウトプットデータ
x_test : testするためのインプットデータ
y_test : testsるためのアウトプットデータ
になるようです。
読みこんだそれぞれのデータをprint文で確認してみます。
x_trainとx_testの中身
まずはx_trainです。
[[[0 0 0 ... 0 0 0]
[0 0 0 ... 0 0 0]
[0 0 0 ... 0 0 0]
...
[0 0 0 ... 0 0 0]
[0 0 0 ... 0 0 0]
[0 0 0 ... 0 0 0]]
[[0 0 0 ... 0 0 0]
[0 0 0 ... 0 0 0]
[0 0 0 ... 0 0 0]
...
[0 0 0 ... 0 0 0]
[0 0 0 ... 0 0 0]
[0 0 0 ... 0 0 0]]
[[0 0 0 ... 0 0 0]
[0 0 0 ... 0 0 0]
[0 0 0 ... 0 0 0]
...
[0 0 0 ... 0 0 0]
[0 0 0 ... 0 0 0]
[0 0 0 ... 0 0 0]]
...
[[0 0 0 ... 0 0 0]
[0 0 0 ... 0 0 0]
[0 0 0 ... 0 0 0]
...
[0 0 0 ... 0 0 0]
[0 0 0 ... 0 0 0]
[0 0 0 ... 0 0 0]]
[[0 0 0 ... 0 0 0]
[0 0 0 ... 0 0 0]
[0 0 0 ... 0 0 0]
...
[0 0 0 ... 0 0 0]
[0 0 0 ... 0 0 0]
[0 0 0 ... 0 0 0]]
[[0 0 0 ... 0 0 0]
[0 0 0 ... 0 0 0]
[0 0 0 ... 0 0 0]
...
[0 0 0 ... 0 0 0]
[0 0 0 ... 0 0 0]
[0 0 0 ... 0 0 0]]]少し分かりづらいですね…。どんな中身なのかしるために
df = pd.DataFrame(X_train[0])
df.to_csv("X_train.csv")を追加してx_trainの最初をcsvで確認します。
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
2 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
3 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
4 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
5 0 0 0 0 0 0 0 0 0 0 0 0 3 18 18 18 126 136 175 26 166 255 247 127 0 0 0 0
6 0 0 0 0 0 0 0 0 30 36 94 154 170 253 253 253 253 253 225 172 253 242 195 64 0 0 0 0
7 0 0 0 0 0 0 0 49 238 253 253 253 253 253 253 253 253 251 93 82 82 56 39 0 0 0 0 0
8 0 0 0 0 0 0 0 18 219 253 253 253 253 253 198 182 247 241 0 0 0 0 0 0 0 0 0 0
9 0 0 0 0 0 0 0 0 80 156 107 253 253 205 11 0 43 154 0 0 0 0 0 0 0 0 0 0
10 0 0 0 0 0 0 0 0 0 14 1 154 253 90 0 0 0 0 0 0 0 0 0 0 0 0 0 0
11 0 0 0 0 0 0 0 0 0 0 0 139 253 190 2 0 0 0 0 0 0 0 0 0 0 0 0 0
12 0 0 0 0 0 0 0 0 0 0 0 11 190 253 70 0 0 0 0 0 0 0 0 0 0 0 0 0
13 0 0 0 0 0 0 0 0 0 0 0 0 35 241 225 160 108 1 0 0 0 0 0 0 0 0 0 0
14 0 0 0 0 0 0 0 0 0 0 0 0 0 81 240 253 253 119 25 0 0 0 0 0 0 0 0 0
15 0 0 0 0 0 0 0 0 0 0 0 0 0 0 45 186 253 253 150 27 0 0 0 0 0 0 0 0
16 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 16 93 252 253 187 0 0 0 0 0 0 0 0
17 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 249 253 249 64 0 0 0 0 0 0 0
18 0 0 0 0 0 0 0 0 0 0 0 0 0 0 46 130 183 253 253 207 2 0 0 0 0 0 0 0
19 0 0 0 0 0 0 0 0 0 0 0 0 39 148 229 253 253 253 250 182 0 0 0 0 0 0 0 0
20 0 0 0 0 0 0 0 0 0 0 24 114 221 253 253 253 253 201 78 0 0 0 0 0 0 0 0 0
21 0 0 0 0 0 0 0 0 23 66 213 253 253 253 253 198 81 2 0 0 0 0 0 0 0 0 0 0
22 0 0 0 0 0 0 18 171 219 253 253 253 253 195 80 9 0 0 0 0 0 0 0 0 0 0 0 0
23 0 0 0 0 55 172 226 253 253 253 253 244 133 11 0 0 0 0 0 0 0 0 0 0 0 0 0 0
24 0 0 0 0 136 253 253 253 212 135 132 16 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
25 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
26 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
27 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
おーなんか数字が見える!なるほどx_trainとx_testは上記のような見た目が数字のデータが入っているようです。
y_trainとy_testの中身
同様にy_trainとy_testを確認すると
[5 0 4 ... 5 6 8]こちらは見た目の数字ではなく、見た目の数字を数字と判断するための数字が格納されているようです。
とりあえず、各データの中身が分かりました。次にデータの前処理について調べていきます。
データの前処理
前処理のコードは
X_train = X_train.reshape((X_train.shape[0], -1)).astype('float32') / 255
X_test = X_test.reshape((X_test.shape[0], -1)).astype('float32') / 255
y_train = to_categorical(y_train, 10)
y_test = to_categorical(y_test, 10)x_trainとx_testの前処理
でした。まずはX_train.reshape((X_train.shape[0], -1)).astype(‘float32’) / 255についてです。
x_trainとx_testのshapeとreshape
X_trainの形状をreshapeして形状を作り変えています。作り変える前の形状をprint(X_train.shape)で確認してみます。
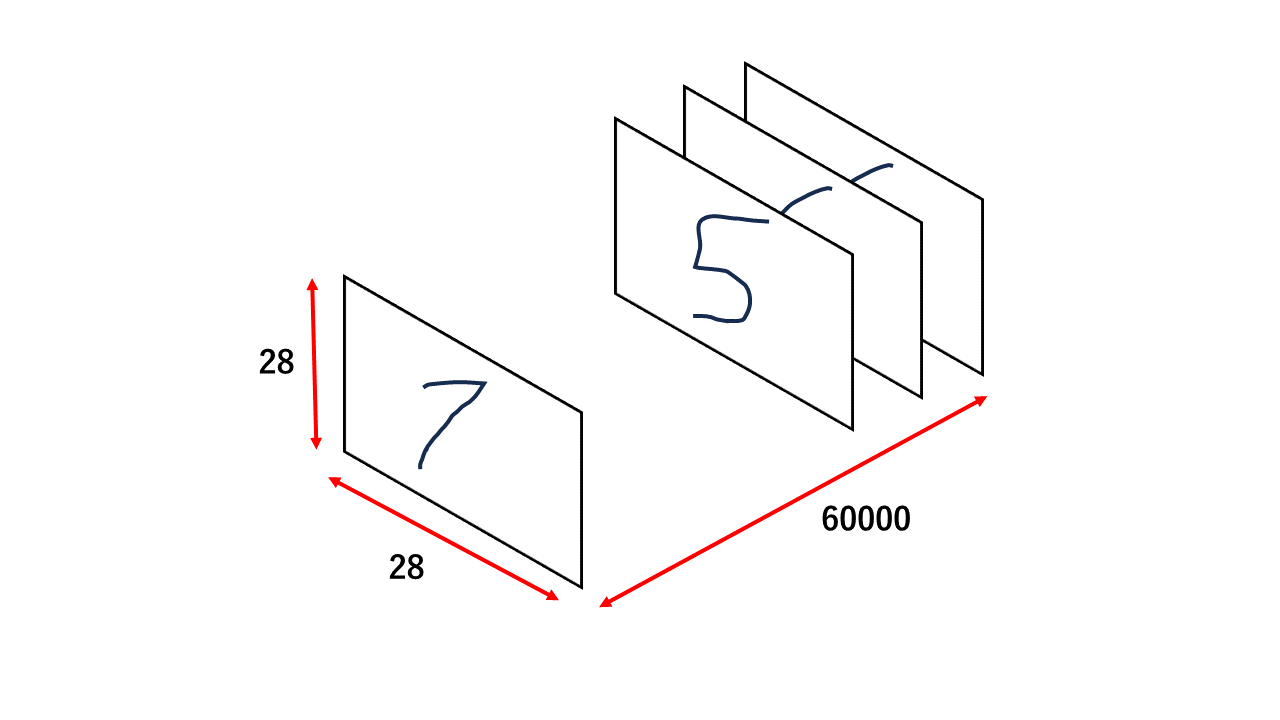
(60000, 28, 28)となりました。3次元形状なので想像は難しそうですが、28×28というのはX_trainのcsvで確認したときの縦×横がちょうど28行28列なので、先ほどのcsvが1/60000のデータなのでしょう。他の59999が見た目の数字データなのでしょう。イメージとしては
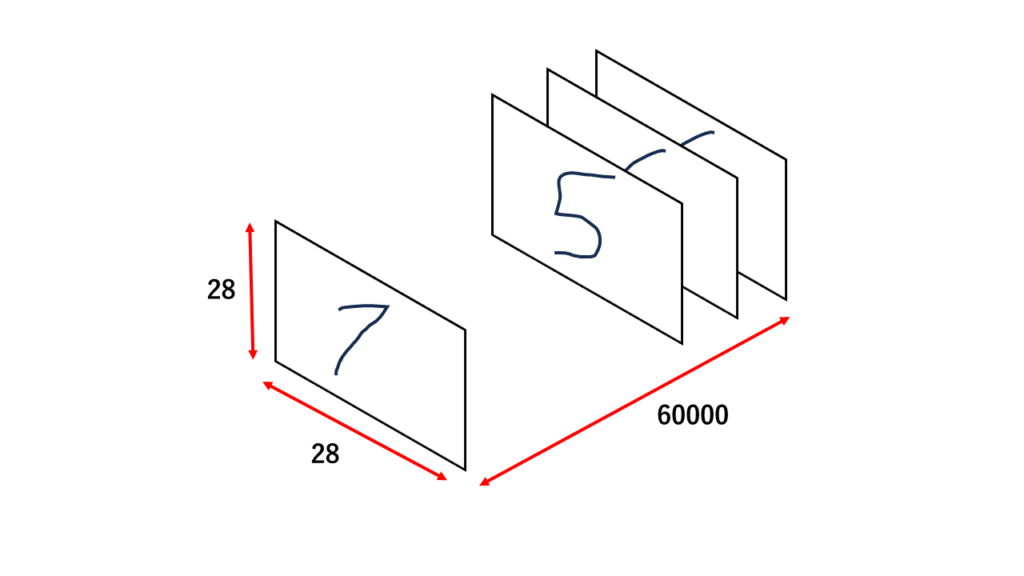
これをreshapeして、(X_train.shape[0], -1))という形状に変更しています。
X_train.shape[0]は上のprintした結果から60000と分かります。-1は逆から並べているように見えますが、一度print(X_train.reshape((X_train.shape[0], -1)))で確認してみましょう。
[[0. 0. 0. ... 0. 0. 0.]
[0. 0. 0. ... 0. 0. 0.]
[0. 0. 0. ... 0. 0. 0.]
...
[0. 0. 0. ... 0. 0. 0.]
[0. 0. 0. ... 0. 0. 0.]
[0. 0. 0. ... 0. 0. 0.]]となりました。0ばかりでよくわかりません。試しにshapeも確認してみましょう。
(60000, 784)となってます。ということは上図の一枚の数字データをさらに1行1行に分けて横に並べているようですね。
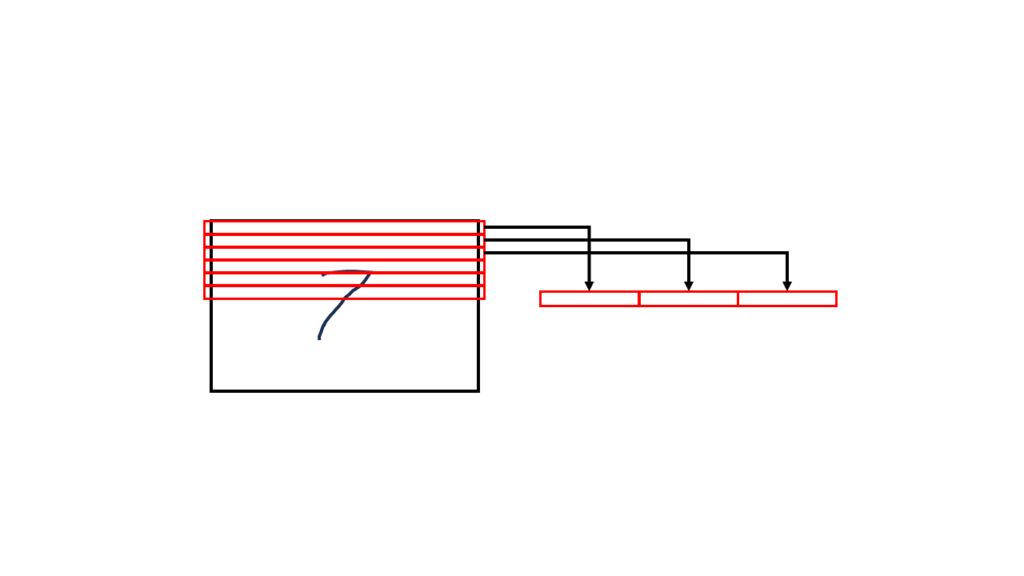
試しに
df = pd.DataFrame(X_train.reshape((X_train.shape[0], -1)))
df.to_csv("X_train_reshape.csv")で確認してみます。csvを乗せようと思ったのですが、重くて載せられませんでしたので、スクリーンショットで
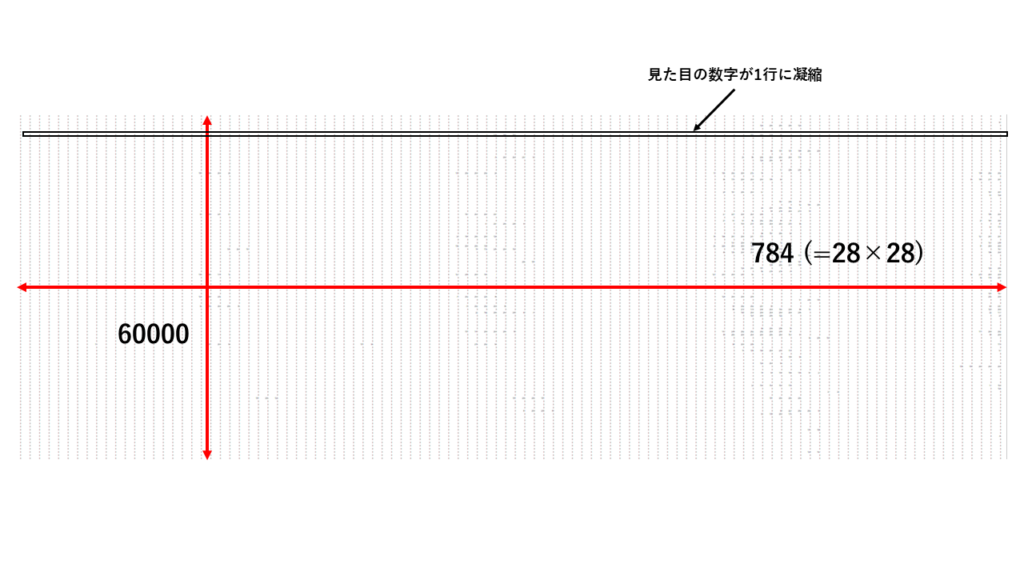
これでreshapeができました。とんでもないデータ量ですね…。
x_trainとx_testのastypeと正規化(ChatGPTにも聞いてみた)
また、前処理に戻って、コードの確認。
X_train = X_train.reshape((X_train.shape[0], -1)).astype('float32') / 255
X_test = X_test.reshape((X_test.shape[0], -1)).astype('float32') / 255
y_train = to_categorical(y_train, 10)
y_test = to_categorical(y_test, 10)astype(‘float32’)はreshapeした数字の型をfloat32に変換してますね。データを見る限りおそらくint型のをfloat型に変えて計算させやすくしているのでしょう。
(一応print(type(X_train.reshape((X_train.shape[0], -1))))で型を調べましたが、ndarrayでした。個々の数字も調べれば多分int型になっているのでしょう)
最後に255で割っています。これは何でしょうか?GTPに聞いてみましょう。(笑)
X_train.reshape((X_train.shape[0], -1)).astype(‘float32’) / 255は何をしているの
X_train.reshape((X_train.shape[0], -1)).astype('float32') / 255 というコードは、ニューラルネットワークの入力用に画像データを前処理するために使用されます。このコードは主に3つのステップで構成されています。
reshape((X_train.shape[0], -1)): この部分は、データセット内の画像を一次元の配列に変換します。X_trainは、通常、形状[数, 高さ, 幅](グレースケール画像の場合)または[数, 高さ, 幅, チャンネル](カラー画像の場合)の3次元または4次元の配列です。reshape((X_train.shape[0], -1))は、最初の次元(画像の数)を維持しながら、残りの次元を一つの次元に平坦化します。これにより、画像データがニューラルネットワークの入力層に適した形状(2次元配列)になります。astype('float32'): この部分は、データの型をfloat32に変換します。多くの画像データセットでは、ピクセルの値が整数(0から255の範囲)で格納されていますが、多くのニューラルネットワークは浮動小数点数を入力として期待しています。astype('float32')は、データ型を浮動小数点数に変換し、計算効率と精度を向上させます。/ 255: この部分は、ピクセル値を0から1の範囲に正規化します。画像データのピクセル値は通常、0から255の範囲で表されます。ニューラルネットワークは入力データが正規化されている場合に効率的に学習するため、ピクセル値を255で割ることで、すべての値が0から1の範囲に収まるようにします。
これらのステップは、ニューラルネットワークの性能を向上させ、より効率的なトレーニングを可能にするための標準的なデータ前処理手順です。
調べた内容も確認できますね。ただ少し抽象的と感じますね。今回は3の255で割って理由です。正規化しているようです。ピクセル値の最大値の255で割ることで255を1としたときの他のピクセル値の割合を求めているみたいです。理由は効率的に学習するためと書かれています。今回はそんな操作があるとしておきましょう。
y_trainとy_testの前処理
長かったですが、最後の前処理です。
y_train = to_categorical(y_train, 10)
y_test = to_categorical(y_test, 10)これは前述したようにy_trainとy_testのデータを10個のラベリングしているようですね。
変換前後をprintで見てみます。
変換前
[5 0 4 ... 5 6 8]変換後
[[0. 0. 0. ... 0. 0. 0.]
[1. 0. 0. ... 0. 0. 0.]
[0. 0. 0. ... 0. 0. 0.]
...
[0. 0. 0. ... 0. 0. 0.]
[0. 0. 0. ... 0. 0. 0.]
[0. 0. 0. ... 0. 1. 0.]]変換前の2つ目の0は変換後の2行目の最初(0)の位置に1とラベリングされています。
変換前の最後の8は変換後の最終行の最後から2番目(8)の位置に1とラベリングされています。
最後に
これでようやく前処理をすべて終わりました。
次回から本格的にAIを動かしてみたいと思います。

コメント