
はじめに
今回はデータを場合分けしたい時や条件によって処理を変えた時などに使える文法を紹介します。以前の記事などで情報を集め、分析することで今後買う株を決めるための意思決定ができます。例えば、分析した結果がある業界に集中投資していた場合、他の業界に投資し分散させるといった意思決定ができます。こういった分析をするための文法になります。今回は以前集約したデータを分析してみたいと思います。
コード
集めた情報を分析するコードです。
import pandas as pd
import matplotlib.pyplot as plt
import japanize_matplotlib
read_data = pd.read_csv("SBIネオモバイルポートフォリオ(csv出力時のファイル名).csv", encoding="Shift-JIS")
fig = plt.figure(figsize=(10, 4.8))
title_name = '現在値(円)'
plt.title(title_name)
plt.pie(read_data[title_name], labels=read_data['銘柄名'], autopct='%1.1f%%', counterclock=False, startangle=90)
plt.axis('equal')
plt.show()
fig.savefig(title_name)
fig = plt.figure(figsize=(10, 4.8))
title_name = '現在値(円)'
plt.title(title_name)
plt.bar(read_data['銘柄名'], read_data[title_name])
plt.xticks(rotation=90)
plt.show()
fig.savefig("bar" + title_name)
fig = plt.figure(figsize=(10, 4.8))
title_name = '評価額(円)'
plt.title(title_name)
plt.bar(read_data['銘柄名'], read_data[title_name])
plt.xticks(rotation=90)
plt.show()
fig.savefig("bar" + title_name)
fig = plt.figure(figsize=(10, 4.8))
title_name = '損益(円)'
plt.title(title_name)
plt.bar(read_data['銘柄名'], read_data[title_name])
plt.xticks(rotation=90)
plt.show()
fig.savefig("bar" + title_name)
fig = plt.figure(figsize=(10, 4.8))
title_name = '保有数量(株)'
plt.title(title_name)
plt.bar(read_data['銘柄名'], read_data[title_name])
plt.xticks(rotation=90)
plt.show()
fig.savefig("bar" + title_name)
fig = plt.figure(figsize=(10, 4.8))
title_name = '現在値(円) x 保有数量(株)'
plt.title(title_name)
plt.pie(read_data['現在値(円)'] * read_data['保有数量(株)'], labels=read_data['銘柄名'], autopct='%1.1f%%', counterclock=False, startangle=90)
plt.axis('equal')
plt.show()
fig.savefig(title_name)
def code(kagen, jougen):
df = read_data[read_data["コード"] >= kagen]
df = df[df["コード"] < jougen]
return df
df_code = pd.DataFrame()
if len(code(1300, 1500)) >= 1:
a = pd.DataFrame(code(1300, 1500).sum())
a.columns = ["農林水産"]
df_code = pd.concat([df_code, a], axis=1)
if len(code(1500, 1700)) >= 1:
a = pd.DataFrame(code(1500, 1700).sum())
a.columns = ["鉱業"]
df_code = pd.concat([df_code, a], axis=1)
if len(code(1700, 2000)) >= 1:
a = pd.DataFrame(code(1700, 2000).sum())
a.columns = ["建設"]
df_code = pd.concat([df_code, a], axis=1)
if len(code(2000, 3000)) >= 1:
a = pd.DataFrame(code(2000, 3000).sum())
a.columns = ["食品"]
df_code = pd.concat([df_code, a], axis=1)
if len(code(3000, 3600)) >= 1:
a = pd.DataFrame(code(3000, 3600).sum())
a.columns = ["繊維製品"]
df_code = pd.concat([df_code, a], axis=1)
if len(code(3700, 4000)) >= 1:
a = pd.DataFrame(code(3000, 4000).sum())
a.columns = ["パルプ・紙"]
df_code = pd.concat([df_code, a], axis=1)
if len(code(4000, 5000)) >= 1:
a = pd.DataFrame(code(4000, 5000).sum())
a.columns = ["化学・医薬品"]
df_code = pd.concat([df_code, a], axis=1)
if len(code(5000, 5100)) >= 1:
a = pd.DataFrame(code(5000, 5100).sum())
a.columns = ["石油・石炭"]
df_code = pd.concat([df_code, a], axis=1)
if len(code(5100, 5200)) >= 1:
a = pd.DataFrame(code(5100, 5200).sum())
a.columns = ["ゴム"]
df_code = pd.concat([df_code, a], axis=1)
if len(code(5200, 5400)) >= 1:
a = pd.DataFrame(code(5200, 5400).sum())
a.columns = ["窯業"]
df_code = pd.concat([df_code, a], axis=1)
if len(code(5400, 5700)) >= 1:
a = pd.DataFrame(code(5400, 5700).sum())
a.columns = ["鉄鋼"]
df_code = pd.concat([df_code, a], axis=1)
if len(code(5700, 5800)) >= 1:
a = pd.DataFrame(code(5700, 5800).sum())
a.columns = ["非鉄金属"]
df_code = pd.concat([df_code, a], axis=1)
if len(code(5900, 6000)) >= 1:
a = pd.DataFrame(code(5900, 6000).sum())
a.columns = ["金属製品"]
df_code = pd.concat([df_code, a], axis=1)
if len(code(6000, 6500)) >= 1:
a = pd.DataFrame(code(6000, 6500).sum())
a.columns = ["機械"]
df_code = pd.concat([df_code, a], axis=1)
if len(code(6500, 7000)) >= 1:
a = pd.DataFrame(code(6500, 7000).sum())
a.columns = ["電気"]
df_code = pd.concat([df_code, a], axis=1)
if len(code(7000, 7500)) >= 1:
a = pd.DataFrame(code(7000, 7500).sum())
a.columns = ["輸送用機械"]
df_code = pd.concat([df_code, a], axis=1)
if len(code(7700, 7800)) >= 1:
a = pd.DataFrame(code(7700, 7800).sum())
a.columns = ["精密機械"]
df_code = pd.concat([df_code, a], axis=1)
if len(code(7800, 8000)) >= 1:
a = pd.DataFrame(code(7800, 8000).sum())
a.columns = ["その他製品"]
df_code = pd.concat([df_code, a], axis=1)
if len(code(8000, 8300)) >= 1:
a = pd.DataFrame(code(8000, 8300).sum())
a.columns = ["商業"]
df_code = pd.concat([df_code, a], axis=1)
if len(code(8300, 8600)) >= 1:
a = pd.DataFrame(code(8300, 8600).sum())
a.columns = ["銀行・ノンバンク"]
df_code = pd.concat([df_code, a], axis=1)
if len(code(8600, 8700)) >= 1:
a = pd.DataFrame(code(8600, 8700).sum())
a.columns = ["証券・証券先物"]
df_code = pd.concat([df_code, a], axis=1)
if len(code(8700, 8800)) >= 1:
a = pd.DataFrame(code(8700, 8800).sum())
a.columns = ["保険"]
df_code = pd.concat([df_code, a], axis=1)
if len(code(8800, 9000)) >= 1:
a = pd.DataFrame(code(8800, 9000).sum())
a.columns = ["不動産"]
df_code = pd.concat([df_code, a], axis=1)
if len(code(9000, 9100)) >= 1:
a = pd.DataFrame(code(9000, 9100).sum())
a.columns = ["陸運"]
df_code = pd.concat([df_code, a], axis=1)
if len(code(9100, 9200)) >= 1:
a = pd.DataFrame(code(9100, 9200).sum())
a.columns = ["海運"]
df_code = pd.concat([df_code, a], axis=1)
if len(code(9200, 9300)) >= 1:
a = pd.DataFrame(code(9200, 9300).sum())
a.columns = ["空運"]
df_code = pd.concat([df_code, a], axis=1)
if len(code(9300, 9400)) >= 1:
a = pd.DataFrame(code(9300, 9400).sum())
a.columns = ["倉庫・運輸"]
df_code = pd.concat([df_code, a], axis=1)
if len(code(9400, 9500)) >= 1:
a = pd.DataFrame(code(9400, 9500).sum())
a.columns = ["情報通信"]
df_code = pd.concat([df_code, a], axis=1)
if len(code(9500, 9600)) >= 1:
a = pd.DataFrame(code(9500, 9600).sum())
a.columns = ["電気ガス"]
df_code = pd.concat([df_code, a], axis=1)
if len(code(9600, 10000)) >= 1:
a = pd.DataFrame(code(9600, 10000).sum())
a.columns = ["サービス"]
df_code = pd.concat([df_code, a], axis=1)
df_code = df_code.T
df_code.to_csv("sector.csv", encoding="Shift-JIS")
df_code["sector"] = df_code.index
fig = plt.figure(figsize=(10, 4.8))
title_name = '現在値(円)'
plt.title(title_name)
plt.pie(df_code[title_name], labels=df_code["sector"], autopct='%1.1f%%', counterclock=False, startangle=90)
plt.axis('equal')
plt.show()
fig.savefig("sector" + title_name)
fig = plt.figure(figsize=(10, 4.8))
title_name = '現在値(円)'
plt.title(title_name)
plt.bar(df_code["sector"], df_code[title_name])
plt.xticks(rotation=90)
plt.show()
fig.savefig("sector" + "bar" + title_name)
fig = plt.figure(figsize=(10, 4.8))
title_name = '評価額(円)'
plt.title(title_name)
plt.bar(df_code["sector"], df_code[title_name])
plt.xticks(rotation=90)
plt.show()
fig.savefig("sector" + "bar" + title_name)
fig = plt.figure(figsize=(10, 4.8))
title_name = '損益(円)'
plt.title(title_name)
plt.bar(df_code["sector"], df_code[title_name])
plt.xticks(rotation=90)
plt.show()
fig.savefig("sector" + "bar" + title_name)
fig = plt.figure(figsize=(10, 4.8))
title_name = '保有数量(株)'
plt.title(title_name)
plt.bar(df_code["sector"], df_code[title_name])
plt.xticks(rotation=90)
plt.show()
fig.savefig("sector" + "bar" + title_name)
fig = plt.figure(figsize=(10, 4.8))
title_name = '現在値(円) x 保有数量(株)'
plt.title(title_name)
plt.pie(df_code['現在値(円)'] * df_code['保有数量(株)'], labels=df_code["sector"], autopct='%1.1f%%', counterclock=False, startangle=90)
plt.axis('equal')
plt.show()
fig.savefig("sector" + title_name)まず、pandasというライブラリで集めた情報を読み込みます。読みこんだデータを個別で分析してみます。上記コードのうち個別で分析しているコードを取り出します。
個別の株で分析する
fig = plt.figure(figsize=(10, 4.8))
title_name = '現在値(円)'
plt.title(title_name)
plt.pie(read_data[title_name], labels=read_data['銘柄名'], autopct='%1.1f%%', counterclock=False, startangle=90)
plt.axis('equal')
plt.show()
fig.savefig(title_name)
fig = plt.figure(figsize=(10, 4.8))
title_name = '現在値(円)'
plt.title(title_name)
plt.bar(read_data['銘柄名'], read_data[title_name])
plt.xticks(rotation=90)
plt.show()
fig.savefig("bar" + title_name)
fig = plt.figure(figsize=(10, 4.8))
title_name = '評価額(円)'
plt.title(title_name)
plt.bar(read_data['銘柄名'], read_data[title_name])
plt.xticks(rotation=90)
plt.show()
fig.savefig("bar" + title_name)
fig = plt.figure(figsize=(10, 4.8))
title_name = '損益(円)'
plt.title(title_name)
plt.bar(read_data['銘柄名'], read_data[title_name])
plt.xticks(rotation=90)
plt.show()
fig.savefig("bar" + title_name)
fig = plt.figure(figsize=(10, 4.8))
title_name = '保有数量(株)'
plt.title(title_name)
plt.bar(read_data['銘柄名'], read_data[title_name])
plt.xticks(rotation=90)
plt.show()
fig.savefig("bar" + title_name)
fig = plt.figure(figsize=(10, 4.8))
title_name = '現在値(円) x 保有数量(株)'
plt.title(title_name)
plt.pie(read_data['現在値(円)'] * read_data['保有数量(株)'], labels=read_data['銘柄名'], autopct='%1.1f%%', counterclock=False, startangle=90)
plt.axis('equal')
plt.show()
fig.savefig(title_name)分析といってもmtplotlibというライブラリでグラフにしているだけです。しかし、これだけでも保有している株を視覚的に情報を得ることができます。
業界で分析する
続いて、業界毎に分析してみたいと思います。(ここからが分岐処理の説明になります。)そのコードが下記のようになります。
def code(kagen, jougen):
df = read_data[read_data["コード"] >= kagen]
df = df[df["コード"] < jougen]
return df
df_code = pd.DataFrame()
if len(code(1300, 1500)) >= 1:
a = pd.DataFrame(code(1300, 1500).sum())
a.columns = ["農林水産"]
df_code = pd.concat([df_code, a], axis=1)
if len(code(1500, 1700)) >= 1:
a = pd.DataFrame(code(1500, 1700).sum())
a.columns = ["鉱業"]
df_code = pd.concat([df_code, a], axis=1)
if len(code(1700, 2000)) >= 1:
a = pd.DataFrame(code(1700, 2000).sum())
a.columns = ["建設"]
df_code = pd.concat([df_code, a], axis=1)
if len(code(2000, 3000)) >= 1:
a = pd.DataFrame(code(2000, 3000).sum())
a.columns = ["食品"]
df_code = pd.concat([df_code, a], axis=1)
if len(code(3000, 3600)) >= 1:
a = pd.DataFrame(code(3000, 3600).sum())
a.columns = ["繊維製品"]
df_code = pd.concat([df_code, a], axis=1)
if len(code(3700, 4000)) >= 1:
a = pd.DataFrame(code(3000, 4000).sum())
a.columns = ["パルプ・紙"]
df_code = pd.concat([df_code, a], axis=1)
if len(code(4000, 5000)) >= 1:
a = pd.DataFrame(code(4000, 5000).sum())
a.columns = ["化学・医薬品"]
df_code = pd.concat([df_code, a], axis=1)
if len(code(5000, 5100)) >= 1:
a = pd.DataFrame(code(5000, 5100).sum())
a.columns = ["石油・石炭"]
df_code = pd.concat([df_code, a], axis=1)
if len(code(5100, 5200)) >= 1:
a = pd.DataFrame(code(5100, 5200).sum())
a.columns = ["ゴム"]
df_code = pd.concat([df_code, a], axis=1)
if len(code(5200, 5400)) >= 1:
a = pd.DataFrame(code(5200, 5400).sum())
a.columns = ["窯業"]
df_code = pd.concat([df_code, a], axis=1)
if len(code(5400, 5700)) >= 1:
a = pd.DataFrame(code(5400, 5700).sum())
a.columns = ["鉄鋼"]
df_code = pd.concat([df_code, a], axis=1)
if len(code(5700, 5800)) >= 1:
a = pd.DataFrame(code(5700, 5800).sum())
a.columns = ["非鉄金属"]
df_code = pd.concat([df_code, a], axis=1)
if len(code(5900, 6000)) >= 1:
a = pd.DataFrame(code(5900, 6000).sum())
a.columns = ["金属製品"]
df_code = pd.concat([df_code, a], axis=1)
if len(code(6000, 6500)) >= 1:
a = pd.DataFrame(code(6000, 6500).sum())
a.columns = ["機械"]
df_code = pd.concat([df_code, a], axis=1)
if len(code(6500, 7000)) >= 1:
a = pd.DataFrame(code(6500, 7000).sum())
a.columns = ["電気"]
df_code = pd.concat([df_code, a], axis=1)
if len(code(7000, 7500)) >= 1:
a = pd.DataFrame(code(7000, 7500).sum())
a.columns = ["輸送用機械"]
df_code = pd.concat([df_code, a], axis=1)
if len(code(7700, 7800)) >= 1:
a = pd.DataFrame(code(7700, 7800).sum())
a.columns = ["精密機械"]
df_code = pd.concat([df_code, a], axis=1)
if len(code(7800, 8000)) >= 1:
a = pd.DataFrame(code(7800, 8000).sum())
a.columns = ["その他製品"]
df_code = pd.concat([df_code, a], axis=1)
if len(code(8000, 8300)) >= 1:
a = pd.DataFrame(code(8000, 8300).sum())
a.columns = ["商業"]
df_code = pd.concat([df_code, a], axis=1)
if len(code(8300, 8600)) >= 1:
a = pd.DataFrame(code(8300, 8600).sum())
a.columns = ["銀行・ノンバンク"]
df_code = pd.concat([df_code, a], axis=1)
if len(code(8600, 8700)) >= 1:
a = pd.DataFrame(code(8600, 8700).sum())
a.columns = ["証券・証券先物"]
df_code = pd.concat([df_code, a], axis=1)
if len(code(8700, 8800)) >= 1:
a = pd.DataFrame(code(8700, 8800).sum())
a.columns = ["保険"]
df_code = pd.concat([df_code, a], axis=1)
if len(code(8800, 9000)) >= 1:
a = pd.DataFrame(code(8800, 9000).sum())
a.columns = ["不動産"]
df_code = pd.concat([df_code, a], axis=1)
if len(code(9000, 9100)) >= 1:
a = pd.DataFrame(code(9000, 9100).sum())
a.columns = ["陸運"]
df_code = pd.concat([df_code, a], axis=1)
if len(code(9100, 9200)) >= 1:
a = pd.DataFrame(code(9100, 9200).sum())
a.columns = ["海運"]
df_code = pd.concat([df_code, a], axis=1)
if len(code(9200, 9300)) >= 1:
a = pd.DataFrame(code(9200, 9300).sum())
a.columns = ["空運"]
df_code = pd.concat([df_code, a], axis=1)
if len(code(9300, 9400)) >= 1:
a = pd.DataFrame(code(9300, 9400).sum())
a.columns = ["倉庫・運輸"]
df_code = pd.concat([df_code, a], axis=1)
if len(code(9400, 9500)) >= 1:
a = pd.DataFrame(code(9400, 9500).sum())
a.columns = ["情報通信"]
df_code = pd.concat([df_code, a], axis=1)
if len(code(9500, 9600)) >= 1:
a = pd.DataFrame(code(9500, 9600).sum())
a.columns = ["電気ガス"]
df_code = pd.concat([df_code, a], axis=1)
if len(code(9600, 10000)) >= 1:
a = pd.DataFrame(code(9600, 10000).sum())
a.columns = ["サービス"]
df_code = pd.concat([df_code, a], axis=1)
df_code = df_code.T
df_code.to_csv("sector.csv", encoding="Shift-JIS")
df_code["sector"] = df_code.index
fig = plt.figure(figsize=(10, 4.8))
title_name = '現在値(円)'
plt.title(title_name)
plt.pie(df_code[title_name], labels=df_code["sector"], autopct='%1.1f%%', counterclock=False, startangle=90)
plt.axis('equal')
plt.show()
fig.savefig("sector" + title_name)
fig = plt.figure(figsize=(10, 4.8))
title_name = '現在値(円)'
plt.title(title_name)
plt.bar(df_code["sector"], df_code[title_name])
plt.xticks(rotation=90)
plt.show()
fig.savefig("sector" + "bar" + title_name)
fig = plt.figure(figsize=(10, 4.8))
title_name = '評価額(円)'
plt.title(title_name)
plt.bar(df_code["sector"], df_code[title_name])
plt.xticks(rotation=90)
plt.show()
fig.savefig("sector" + "bar" + title_name)
fig = plt.figure(figsize=(10, 4.8))
title_name = '損益(円)'
plt.title(title_name)
plt.bar(df_code["sector"], df_code[title_name])
plt.xticks(rotation=90)
plt.show()
fig.savefig("sector" + "bar" + title_name)
fig = plt.figure(figsize=(10, 4.8))
title_name = '保有数量(株)'
plt.title(title_name)
plt.bar(df_code["sector"], df_code[title_name])
plt.xticks(rotation=90)
plt.show()
fig.savefig("sector" + "bar" + title_name)
fig = plt.figure(figsize=(10, 4.8))
title_name = '現在値(円) x 保有数量(株)'
plt.title(title_name)
plt.pie(df_code['現在値(円)'] * df_code['保有数量(株)'], labels=df_code["sector"], autopct='%1.1f%%', counterclock=False, startangle=90)
plt.axis('equal')
plt.show()
fig.savefig("sector" + title_name)分岐で分析する
長いコードですが、ifで書かれている部分が該当箇所です。文法としてはif ~~~:です。~~~は論理演算が入ります。論理演算については別の記事で書きます。意味は「もし~~~が満たしたら:より下を実行してください。それ以外なら:より下の実行は無視してください」となります。~~~でいろいろな分岐ができます。今回の場合、code(kagen,jougen)という自作の関数(これも別の記事で説明します)で「kagen以上、jougenn以下の証券コードが存在したら:より下を実行してください。」としています。ただ、存在しているかの確認を行数で判定しています。行数が0よりおおければ存在していて、それ以外は存在していないように判定しています。行数を判定するのにlen()という関数を使って判定しています。if ~~~:の~~~は自分のコードや読みやすさで決めるといいかもしれません。ここまで文章だとイメージが沸きずらいとおもいますので、下図のようにイメージすると理解しやすいかと思います。
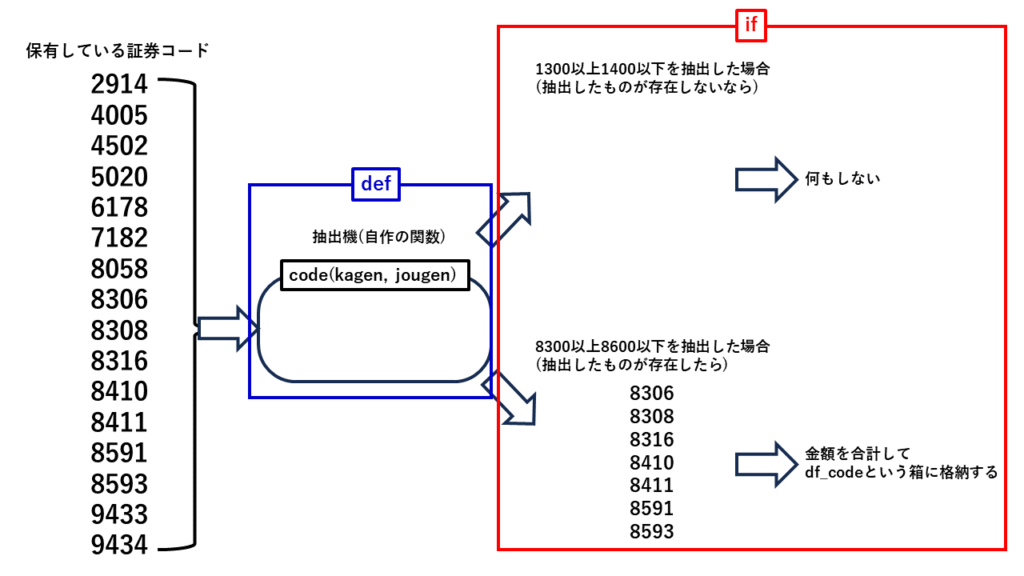
保有している証券コードから抽出機を使って抽出します。その抽出した結果がifの条件を満たさないときは何もせず、満たせばデータを処理します。処理の仕方はデータに格納という処理をしますが、これはこの記事を参照してください。この格納という処理はループとも相性が良いですが、本記事のように分岐とも相性が良い処理になります。是非試してください。
分岐の処理が終わって、データを振り分けた後のデータをmatplotlibというグラフを描くライブラリで可視化します。これで各業界ごとのデータ処理を分析することができます。上記図では銀行系が多いことが分かりますので、他の業界に投資しようと意思決定ができるかと思います。
最後に
今回は集約したデータをより詳細に分析できるようにしました。特に分岐という手法を使って分類することを紹介しました。論理演算は自由に変えられる分、難しいところが多いと思いますが、いろいろ試してみて自分が使いやすい方法など探してみましょう。コツなどは他の記事で紹介できたらと思います。
2023/08/28 J.A

コメント