はじめに
前回はRNNの概要について調べました。
今回からChatGPTに聞いたコードを勉強していき、RNNを実装できるようにしていきたいと思います。
RNNのコードについて勉強してみた
コード
import numpy as np
import matplotlib.pyplot as plt
def sigmoid(x):
return 1 / (1 + np.exp(-x))
# RNNセルの定義
class SimpleRNNCell:
def __init__(self, input_size, hidden_size):
self.input_size = input_size
self.hidden_size = hidden_size
# 重み行列の初期化
self.Wx = np.random.randn(hidden_size, input_size)
self.Wh = np.random.randn(hidden_size, hidden_size)
self.b = np.zeros((hidden_size, 1))
def forward(self, x, h_prev):
# 順伝播
self.x = x
self.h_prev = h_prev
self.a = np.dot(self.Wx, x) + np.dot(self.Wh, h_prev) + self.b
self.h = np.tanh(self.a)
return self.h
def backward(self, dh_next):
# 逆伝播
da = dh_next * (1 - np.tanh(self.a)**2)
self.db = np.sum(da, axis=1, keepdims=True)
self.dWh = np.dot(da, self.h_prev.T)
self.dWx = np.dot(da, self.x.T)
self.dx = np.dot(self.Wh.T, da)
self.dh_prev = np.dot(self.Wx.T, da)
return self.dx, self.dh_prev
def update_parameters(self, learning_rate):
# 重みの更新
self.Wx -= learning_rate * self.dWx
self.Wh -= learning_rate * self.dWh
self.b -= learning_rate * self.db
# サンプルデータの生成
seq_length = 5
input_size = 10
hidden_size = input_size
fig = plt.figure()
# 入力データ (shape: (input_size, seq_length))
X = np.random.randn(input_size, seq_length)
print(X)
ax1 = fig.add_subplot(3, 1, 1)
ax1.plot(range(len(X)), X, marker="o")
ax1.set_ylabel("input")
# 目標出力 (仮の値)
y = np.random.randn(hidden_size, 1)
print(y)
ax2 = fig.add_subplot(3, 1, 2)
ax2.plot(range(len(y)), y, label="original")
ax2.set_ylabel("output")
# 初期隠れ状態 (shape: (hidden_size, 1))
h0 = np.zeros((hidden_size, 1))
# RNNセルの作成
rnn_cell = SimpleRNNCell(seq_length, hidden_size)
# 順伝播
h_t = h0
epochs = 100
loss_list = []
for epoch in range(epochs):
for t in range(input_size):
x_t = X[t, :].reshape(-1, 1)
h_t = rnn_cell.forward(x_t, h_t)
# 仮の損失関数 (例: 平均二乗誤差)
loss = np.mean((h_t - y)**2)
loss_list.append(loss)
# 逆伝播
dh_next = 2 * (h_t - y) # 仮の勾配
dx, dh_prev = rnn_cell.backward(dh_next)
# 重みの更新
learning_rate = 0.01
rnn_cell.update_parameters(learning_rate)
print(loss)
ax2.plot(range(len(y)), h_t, marker="o", label="predict")
ax2.legend(loc="upper left")
ax3 = fig.add_subplot(3, 1, 3)
ax3.plot(range(epochs)[1:], loss_list[1:], marker="o")
ax3.set_ylabel("loss")
ax3.set_yscale('log')
x_t = X[-1, :].reshape(-1, 1)
pred = rnn_cell.forward(x_t, h_t)[-1]調べてみた
今回はRNNというよりもインプットデータと正解のデータの準備と可視化ですね。
あとはRNNの隠れ層もインプットデータの一つになるので初期値も準備する必要があるようなので、その実装ですね。
該当となる箇所は以下になります。
# サンプルデータの生成
seq_length = 5
input_size = 10
hidden_size = input_size
fig = plt.figure()
# 入力データ (shape: (input_size, seq_length))
X = np.random.randn(input_size, seq_length)
print(X)
ax1 = fig.add_subplot(3, 1, 1)
ax1.plot(range(len(X)), X, marker="o")
ax1.set_ylabel("input")
# 目標出力 (仮の値)
y = np.random.randn(hidden_size, 1)
print(y)
ax2 = fig.add_subplot(3, 1, 2)
ax2.plot(range(len(y)), y, label="original")
ax2.set_ylabel("output")
# 初期隠れ状態 (shape: (hidden_size, 1))
h0 = np.zeros((hidden_size, 1))インプットデータの用意
インプットデータとなるXはnp.random.randnは平均0、標準偏差1の正規分布の乱数を生成する関数なようで、こちらで詳しく解説されてます。
よくわからない方は適当な数字を作っているんだなと思ってください。(自分もきちんと説明できるほどでないです…。)
ここで重要なのはデータの形状だと思っています。今回は変数で扱っていますが、
seq_length = 5
input_size = 10が形状を決めています。
これをprintすると以下のような数字が
[[ 1.5611163 0.26050542 -2.35541371 -0.72715361 -1.75803683]
[ 1.12914253 -0.02260556 -0.48790594 0.5623382 0.49305105]
[ 0.49448774 1.75755383 -0.51121909 2.46924625 -1.0138211 ]
[ 1.37351542 0.93243859 -1.53503702 0.12580747 -0.63957164]
[ 0.16859157 0.24646808 -0.35491496 -0.8493017 1.00615459]
[-1.52563937 -0.1317426 -0.87912859 -0.69296951 0.13920365]
[-2.123731 -0.11564609 0.68898755 -1.5132858 0.40566622]
[ 0.40777054 -0.56260697 -0.58658686 -0.82459102 -2.71945497]
[ 0.31428287 0.85702085 -0.54486851 1.08566984 0.66942539]
[-0.45267791 0.82724751 1.53645049 -0.95685793 -1.32835139]]縦が10行、横が5列の行列です。先ほどの変数に対応した形状が作成されます。
RNNのインプットデータとしては5種類の変数(例えば、天気の予測した場合、温度、湿度、風向きなどが変数になります)を10個の時間データと解釈できるかなと思います。
正解データの用意
同様に正解データyについてです。こちらもnp.random.randnでランダムに数字を作成しています。形状はインプットデータに合わせて10行のデータですが、種類は1つにしました。
これの解釈として、インプットデータの各時間で一つのデータが出力されているようなイメージです。例えば、温度、湿度、風向きなどから晴れ、雨、曇りなどの天気が出力されるようなイメージです。
これをprintすると、以下に出力されます。
[[ 0.21260526]
[ 1.20331487]
[-0.00140236]
[ 0.39661954]
[ 0.98709297]
[-0.42189847]
[ 0.5148049 ]
[-0.61740502]
[-0.81302843]
[-0.32058559]]RNNでのインプットデータと正解データのイメージ
Xとyを図でイメージすると以下のようになるかと思います。
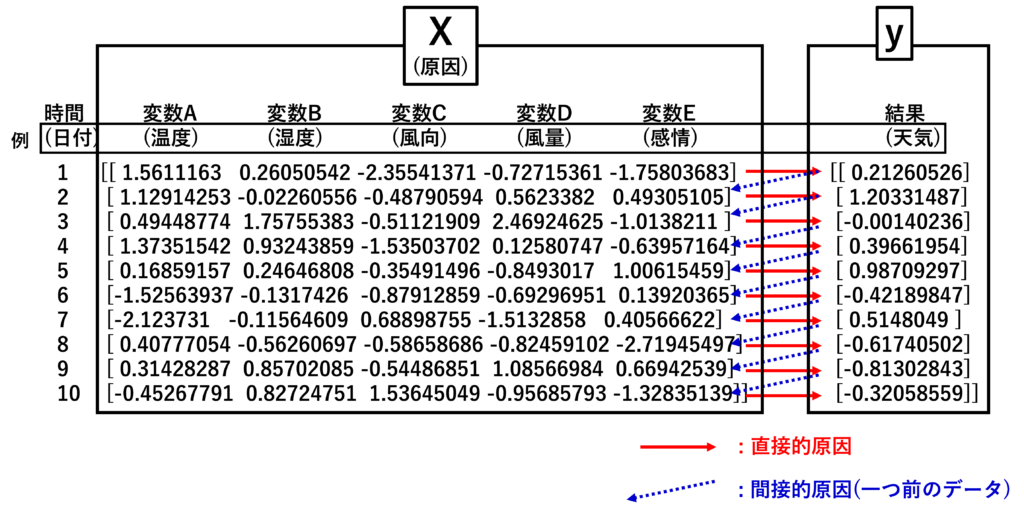
多分なのですが、RNNでは原因となるXから結果yを予測し、プラスし一つ前のデータを使って予測しているのではないかと思っています。ここでは直接的原因と間接的原因と呼んでいます。
通常のAI(DNN)では間接的原因がないものを指しているので、データを読みこむときは全データを一気に読みこんで予測できると思っています。
RNNの場合は、1行ずつ読みこんで、予測。その予測から次のデータを予測と次々と行っていると思っています。
一つ一つ読みこんで予測という連続的な動作を行うためには隠れ層を共有してそれぞれのデータに適合していく必要があると考えられます。
そこで、隠れ層を動的に変化させるためには最初の状態を設定して、最初の状態を少しずつ変えるという手法が作られたようです。
隠れ層の準備
そのため、隠れ層の初期状態を実装します。それが、
# 初期隠れ状態 (shape: (hidden_size, 1))
h0 = np.zeros((hidden_size, 1))になります。ここでは要素が0の行列を作っているようです。形状はyと同じとなっていますので、yと同じだけのニューロンが隠れ層になっているようです。
この初期の隠れ層から徐々に要素の数字を変えて、最適な値を見つけていくことがRNNの特徴のようです。
最後に
今回のコードの解説はRNNの中でも比較的簡単(?)な方のものだと思いますが、考え方が少し難しいかったですね。次回からもっと大変になるかもしれませんが、頑張っていきます。

コメント